StarPU runtime system (part 2)¶
Objectives
Understand more about StarPU
Understand how StarPU supports distributed memory
Understand how StarPU supports GPUs
Data handles and interfaces¶
A task implementation should not modify the task arguments as these changes are not propagated to the other tasks. Furthermore, the task arguments do not induce any task dependencies. They are therefore only suitable for passing static arguments to the tasks.
Data handles are much more flexible as any modification made in one task are passed to the other tasks and these changes also induce task dependencies. A data handle (starpu_data_handle_t) can encapsulate any conceivable data type. However, the built-in data interfaces for scalars, vectors and matrices are adequate for many use cases:
void starpu_variable_data_register (starpu_data_handle_t *handle,
int home_node,
uintptr_t ptr,
size_t size
)
#define STARPU_VARIABLE_GET_PTR (interface)
#define STARPU_VARIABLE_GET_ELEMSIZE (interface)
Above, home_node is the memory node where the variable is initially stored. In most cases, the variable is initially stored in the main memory (STARPU_MAIN_RAM). The argument ptr is a pointer to the variable (in the main memory) and the argument size is the size of the variable.
void starpu_vector_data_register (starpu_data_handle_t * handle,
int home_node,
uintptr_t ptr,
uint32_t nx,
size_t elemsize
)
#define STARPU_VECTOR_GET_PTR (interface)
#define STARPU_VECTOR_GET_NX (interface)
#define STARPU_VECTOR_GET_ELEMSIZE (interface)
Above, the argument nx is the length of the vector and the argument elemsize is the size of a vector element.
void starpu_matrix_data_register (starpu_data_handle_t * handle,
int home_node,
uintptr_t ptr,
uint32_t ld,
uint32_t nx,
uint32_t ny,
size_t elemsize
)
#define STARPU_MATRIX_GET_PTR (interface)
#define STARPU_MATRIX_GET_NX (interface)
#define STARPU_MATRIX_GET_NY (interface)
#define STARPU_MATRIX_GET_LD (interface)
#define STARPU_MATRIX_GET_ELEMSIZE (interface)
Above, the argument ld is the leading dimension of the matrix (row-major order), the argument xn is the width of the matrix and the argument ny is the height of the matrix.
For example, the following example allocates a matrix and initializes a data handle that encapsulates the matrix:
1 2 3 4 | double *matrix = malloc(width * ld * sizeof(double));
starpu_data_handle_t handle;
starpu_matrix_data_register(&handle, STARPU_MAIN_RAM,
(uintptr_t)matrix, ld, height, width, sizeof(double));
|
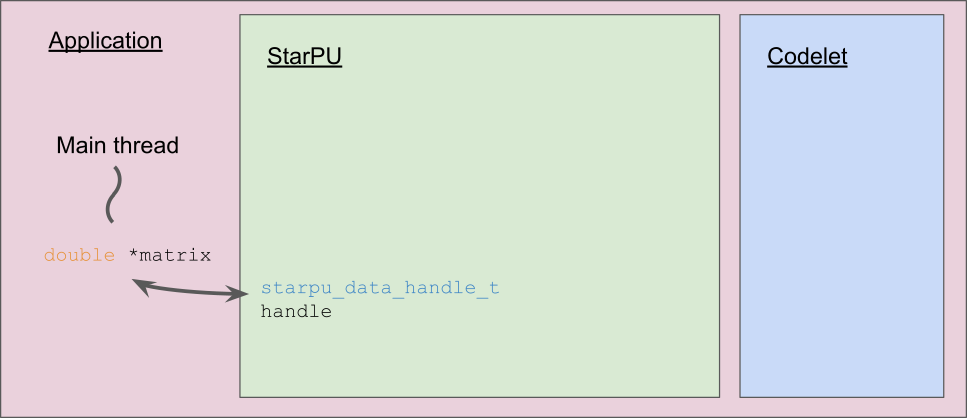
Data handles.¶
The above example assumes that the matrix is stored in column-major order.
Each data handle must be unregistered before the main thread can access it again:
starpu_data_unregister(handle);
This blocks the main thread until all related tasks have been executed.
The easiest way to pass a data handle to a task is to declare it in the related codelet:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | struct starpu_codelet
{
uint32_t where;
int (*can_execute)(unsigned workerid, struct starpu_task *task, unsigned nimpl);
enum starpu_codelet_type type;
int max_parallelism;
starpu_cpu_func_t cpu_func STARPU_DEPRECATED;
starpu_cuda_func_t cuda_func STARPU_DEPRECATED;
starpu_opencl_func_t opencl_func STARPU_DEPRECATED;
starpu_cpu_func_t cpu_funcs[STARPU_MAXIMPLEMENTATIONS];
starpu_cuda_func_t cuda_funcs[STARPU_MAXIMPLEMENTATIONS];
char cuda_flags[STARPU_MAXIMPLEMENTATIONS];
starpu_opencl_func_t opencl_funcs[STARPU_MAXIMPLEMENTATIONS];
char opencl_flags[STARPU_MAXIMPLEMENTATIONS];
starpu_mic_func_t mic_funcs[STARPU_MAXIMPLEMENTATIONS];
starpu_mpi_ms_func_t mpi_ms_funcs[STARPU_MAXIMPLEMENTATIONS];
const char *cpu_funcs_name[STARPU_MAXIMPLEMENTATIONS];
int nbuffers;
enum starpu_data_access_mode modes[STARPU_NMAXBUFS];
enum starpu_data_access_mode *dyn_modes;
unsigned specific_nodes;
int nodes[STARPU_NMAXBUFS];
int *dyn_nodes;
struct starpu_perfmodel *model;
struct starpu_perfmodel *energy_model;
unsigned long per_worker_stats[STARPU_NMAXWORKERS];
const char *name;
unsigned color;
int flags;
int checked;
};
|
The nbuffers field stores the total number of data handles the task accepts and the modes field tabulates an access mode for each data handle. The access mode can be one of the following:
- STARPU_NONE
Not documented.
- STARPU_R
Read-only mode.
- STARPU_W
Write-only mode.
- STARPU_RW
Read-write mode. Equivalent to STARPU_R | STARPU_W.
- STARPU_SCRATCH
Scratch buffer (one per device).
- STARPU_REDUX
The data handle is used in a reduction-type operation.
- STARPU_COMMUTE
Tasks can access this variable in an arbitrary order.
- STARPU_SSEND
The data has to be sent using a synchronous and non-blocking mode (StarPU-MPI).
- STARPU_LOCALITY
Tells the scheduler that the data handle is sensitive to data locality.
- STARPU_ACCESS_MODE_MAX
Not documented.
Note that this limits the number of data handles passed to a task to STARPU_NMAXBUFS. Furthermore, all tasks of a particular type must accept the same number of data handles. The number of data handles passed to a codelet can be arbitrary but this feature is not covered during this course.
For example, the following example defines a codelet that accepts a single read-write data handle:
1 2 3 4 5 6 | struct starpu_codelet codelet =
{
.cpu_funcs = { func },
.nbuffers = 1,
.modes = { STARPU_RW }
};
|
The data handles are passed to the starpu_task_insert function:
1 2 3 4 5 | starpu_task_insert(
&codelet,
STARPU_RW,
handle,
0);
|
Finally, the task implementation extracts a matching data interface from the implementation arguments:
1 2 3 4 5 6 7 8 9 10 11 12 | void func(void *buffers[], void *args)
{
struct starpu_matrix_interface *interface =
(struct starpu_matrix_interface *)buffers[0];
double *ptr = (double *) STARPU_MATRIX_GET_PTR(interface);
int height = STARPU_MATRIX_GET_NX(interface);
int width = STARPU_MATRIX_GET_NY(interface);
int ld = STARPU_MATRIX_GET_LD(interface);
process(height, width, ld, ptr);
}
|

Data interfaces. The pointers matrix and ptr do not necessarily point to the same memory location.¶
The runtime system guarantees that data resides in the device memory when a worker thread starts executing the task. If necessary, StarPU copies the data from one memory space to another. The scalar and vector data handles have their own interfaces: starpu_variable_interface and starpu_vector_interface.
If two tasks are given the same data handle in their argument lists, then an implicit data dependency may be induced between the tasks:
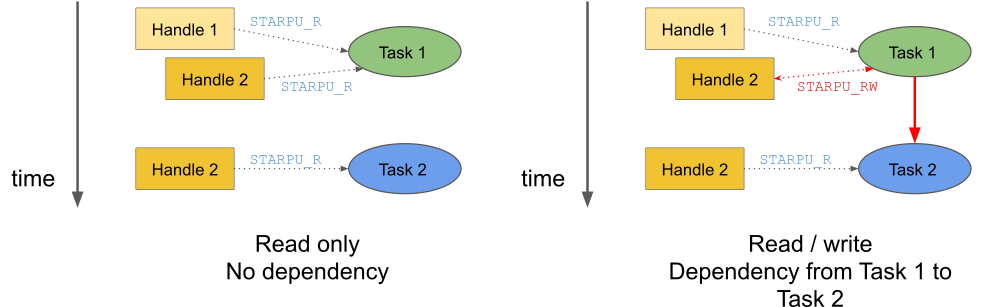
Two examples of data dependencies¶
Challenge
Modify the example below as follows:
Write a new task implementation (add_cpu) that
accepts three data handles (variable / int) as arguments (buffers[0], buffers[1] and buffers[2]),
extracts the data interfaces from buffers: a_i, b_i and c_i
adds up the first two arguments and stores the result to the third argument.
Write the corresponding codelet (add_cl).
Remember, the first two data handles are STARPU_R and the third STARPU_W.
Create three integer variables (int): a, b and c. Initialize b to 7.
Register a data handle for each variable: a_h, b_h and c_h.
Insert an init_cl task that initializes a_h to 10.
Insert an add_cl task and give a_h, b_h and c_h as arguments.
Unregister a_h, b_h and c_h.
Print the variables a, b and c.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | #include <stdio.h>
#include <starpu.h>
// a task implementation that initializes a variable to 10
void init_cpu(void *buffers[], void *cl_arg)
{
struct starpu_variable_interface *a_i =
(struct starpu_variable_interface *) buffers[0];
int *a = (int *) STARPU_VARIABLE_GET_PTR(a_i);
*a = 10;
}
// a task implementation that adds two numbers and return the sum
struct starpu_codelet init_cl = {
.cpu_funcs = { init_cpu },
.nbuffers = 1,
.modes = { STARPU_W }
};
int main()
{
int a;
if (starpu_init(NULL) != 0)
printf("Failed to initialize Starpu.\n");
// initialize all data handles
starpu_data_handle_t a_h;
starpu_variable_data_register(
&a_h, STARPU_MAIN_RAM, (uintptr_t)&a, sizeof(a));
// insert tasks
starpu_task_insert(&init_cl, STARPU_W, a_h, 0);
// unregister all data handles
starpu_data_unregister(a_h);
printf("%d\n", a);
starpu_shutdown();
return 0;
}
|
Solution
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 | #include <stdio.h>
#include <starpu.h>
// a task implementation that initializes a variable to 10
void init_cpu(void *buffers[], void *cl_arg)
{
struct starpu_variable_interface *a_i =
(struct starpu_variable_interface *) buffers[0];
int *a = (int *) STARPU_VARIABLE_GET_PTR(a_i);
*a = 10;
}
// a task implementation that adds two numbers and returns the sum
void add_cpu(void *buffers[], void *cl_arg)
{
struct starpu_variable_interface *a_i =
(struct starpu_variable_interface *) buffers[0];
int *a = (int *) STARPU_VARIABLE_GET_PTR(a_i);
struct starpu_variable_interface *b_i =
(struct starpu_variable_interface *) buffers[1];
int *b = (int *) STARPU_VARIABLE_GET_PTR(b_i);
struct starpu_variable_interface *c_i =
(struct starpu_variable_interface *) buffers[2];
int *c = (int *) STARPU_VARIABLE_GET_PTR(c_i);
*c = *a + *b;
}
// initialization codelet
struct starpu_codelet init_cl = {
.cpu_funcs = { init_cpu },
.nbuffers = 1,
.modes = { STARPU_W }
};
// addition codelet
struct starpu_codelet add_cl = {
.cpu_funcs = { add_cpu },
.nbuffers = 3,
.modes = { STARPU_R, STARPU_R, STARPU_W }
};
int main()
{
int a, b = 7, c;
if (starpu_init(NULL) != 0)
printf("Failed to initialize Starpu.\n");
// initialize all data handles
starpu_data_handle_t a_h, b_h, c_h;
starpu_variable_data_register(
&a_h, STARPU_MAIN_RAM, (uintptr_t)&a, sizeof(a));
starpu_variable_data_register(
&b_h, STARPU_MAIN_RAM, (uintptr_t)&b, sizeof(b));
starpu_variable_data_register(
&c_h, STARPU_MAIN_RAM, (uintptr_t)&c, sizeof(c));
// insert tasks
starpu_task_insert(&init_cl, STARPU_W, a_h, 0);
starpu_task_insert(&add_cl, STARPU_R, a_h, STARPU_R, b_h, STARPU_W, c_h, 0);
// unregister all data handles
starpu_data_unregister(a_h);
starpu_data_unregister(b_h);
starpu_data_unregister(c_h);
printf("%d + %d = %d\n", a, b, c);
starpu_shutdown();
return 0;
}
|
$ gcc -o starpu_program starpu_program.c -Wall -lstarpu-1.3
$ ./starpu_program
10 + 7 = 17
Distributed memory¶
StarPU supports distributed memory through MPI in three different ways:
Without StarPU-MPI.
A programmer must manually transfer the data between StarPU data handles and MPI.
Not generally recommended but might be a good stopgap solution.
With StarPU-MPI.
A programmer replaces the
MPI_Recv()andMPI_Send()calls withstarpu_mpi_irecv_detached()andstarpu_mpi_isend_detached()calls. These functions act directly on the StarPU data handles.With MPI Insert Task Utility.
A programmer replaces the
starpu_task_insert()calls withstarpu_mpi_task_insert()calls. In addition, one must use thestarpu_mpi_data_register()function to tell which MPI process owns each data handle.
The second and third approach allocate one CPU core for MPI communications.
In the third approach, the starpu_mpi_task_insert() function takes into account the task dependencies and the data distribution, and generates the necessary communication pattern automatically:
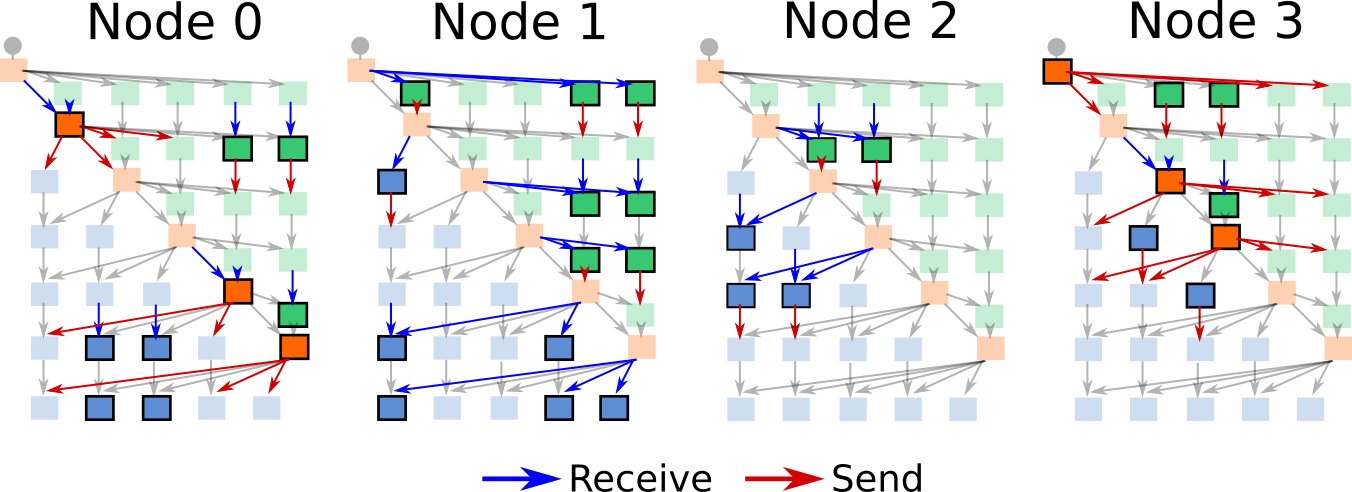
In the above illustration, each MPI process has a copy of the entire task graph. Two things can happen:
If the MPI process is going to execute a task, it can receive any missing data handle from the MPI process that owns the data handle.
If the MPI process is not going to execute a task, it will send any data handles it owns to the MPI process that is going to execute the task.
This all happens automatically and asynchronously. The task implementations do not require any modifications! StarPU-MPI also implements a MPI cache that caches data handles that were not modified.
Consider the following example where each MPI process writes its rank to a data handle and then passes it to the neighbouring MPI process:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 | #include <stdio.h>
#include <starpu.h>
#include <starpu_mpi.h>
// a codelet that initializes a data handle with a MPI process' world rank
void write_number_cpu(void *buffers[], void *cl_arg)
{
int world_rank = starpu_mpi_world_rank();
int *value = (int *) STARPU_VARIABLE_GET_PTR(buffers[0]);
*value = world_rank;
printf("Rank %d writes value %d.\n", world_rank, *value);
}
struct starpu_codelet write_number_cl = {
.cpu_funcs = { write_number_cpu },
.nbuffers = 1,
.modes = { STARPU_W }
};
// a codelet that prints the contents of a data handle
void read_number_cpu(void *buffers[], void *cl_arg)
{
int world_rank = starpu_mpi_world_rank();
int value = *((int *) STARPU_VARIABLE_GET_PTR(buffers[0]));
printf("Rank %d reads value %d.\n", world_rank, value);
}
struct starpu_codelet read_number_cl = {
.cpu_funcs = { read_number_cpu },
.nbuffers = 1,
.modes = { STARPU_R }
};
int main(int argc, char **argv) {
// initialize MPI
int thread_support;
MPI_Init_thread(
&argc, (char ***)&argv, MPI_THREAD_MULTIPLE, &thread_support);
// initialize StarPU
if (starpu_init(NULL) != 0)
printf("Failed to initialize Starpu.\n");
// initialize StarPU-MPI
if (starpu_mpi_init(&argc, &argv, 0) != 0)
printf("Failed to initialize Starpu-MPI.\n");
// query world communicator's size
int world_size = starpu_mpi_world_size();
// initialize all data handles
starpu_data_handle_t handles[world_size];
for (int i = 0; i < world_size; i++) {
// register a data handle that is going to be initialized later
starpu_variable_data_register(
&handles[i], -1, (uintptr_t) NULL, sizeof(int));
// register data handle's owner and tag
starpu_mpi_data_register(handles[i], i, i);
}
// insert tasks that initialize the data handles
for (int i = 0; i < world_size; i++)
starpu_mpi_task_insert(
MPI_COMM_WORLD, &write_number_cl,
STARPU_EXECUTE_ON_DATA, handles[i], // data handles owner executes
STARPU_W, handles[i], 0);
// insert tasks that print the data handles
for (int i = 0; i < world_size; i++)
starpu_mpi_task_insert(
MPI_COMM_WORLD, &read_number_cl,
STARPU_EXECUTE_ON_NODE, i, // rank i executes
STARPU_R, handles[(i+1)%world_size], 0);
// unregister all data handles
for (int i = 0; i < world_size; i++)
starpu_data_unregister(handles[i]);
// de-initialize everything
starpu_mpi_shutdown();
starpu_shutdown();
MPI_Finalize();
return 0;
}
|
We are going to launch four MPI processes and allocate two CPU cores for each process:
$ gcc -o my_program my_program.c -lstarpu-1.3 -lstarpumpi-1.3 -lmpi -Wall
$ STARPU_WORKERS_NOBIND=1 mpirun -n 4 --map-by :PE=2 ./my_program
Rank 1 writes value 1.
Rank 0 writes value 0.
Rank 2 writes value 2.
Rank 3 reads value 0.
Rank 3 writes value 3.
Rank 0 reads value 1.
Rank 1 reads value 2.
Rank 2 reads value 3.
Accelerators¶
As you may remember, a StarPU codelet included a field for CUDA implementations:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | struct starpu_codelet
{
uint32_t where;
int (*can_execute)(unsigned workerid, struct starpu_task *task, unsigned nimpl);
enum starpu_codelet_type type;
int max_parallelism;
starpu_cpu_func_t cpu_func STARPU_DEPRECATED;
starpu_cuda_func_t cuda_func STARPU_DEPRECATED;
starpu_opencl_func_t opencl_func STARPU_DEPRECATED;
starpu_cpu_func_t cpu_funcs[STARPU_MAXIMPLEMENTATIONS];
starpu_cuda_func_t cuda_funcs[STARPU_MAXIMPLEMENTATIONS];
char cuda_flags[STARPU_MAXIMPLEMENTATIONS];
starpu_opencl_func_t opencl_funcs[STARPU_MAXIMPLEMENTATIONS];
char opencl_flags[STARPU_MAXIMPLEMENTATIONS];
starpu_mic_func_t mic_funcs[STARPU_MAXIMPLEMENTATIONS];
starpu_mpi_ms_func_t mpi_ms_funcs[STARPU_MAXIMPLEMENTATIONS];
const char *cpu_funcs_name[STARPU_MAXIMPLEMENTATIONS];
int nbuffers;
enum starpu_data_access_mode modes[STARPU_NMAXBUFS];
enum starpu_data_access_mode *dyn_modes;
unsigned specific_nodes;
int nodes[STARPU_NMAXBUFS];
int *dyn_nodes;
struct starpu_perfmodel *model;
struct starpu_perfmodel *energy_model;
unsigned long per_worker_stats[STARPU_NMAXWORKERS];
const char *name;
unsigned color;
int flags;
int checked;
};
|
Unfortunately we do not have time to cover all the complexities related to GPU offloading. Instead, we will simply consider the following example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | #include <stdio.h>
#include <starpu.h>
void hello_world_cpu(void *buffers[], void *cl_arg)
{
printf("The host says, Hello world!\n");
}
__global__ void say_hello()
{
printf("A device says, Hello world!\n");
}
void hello_world_cuda(void *buffers[], void *cl_arg)
{
cudaStream_t stream = starpu_cuda_get_local_stream();
say_hello<<<1, 1 , 0, stream>>>();
cudaError err = cudaStreamSynchronize(stream);
if (err != cudaSuccess)
STARPU_CUDA_REPORT_ERROR(err);
}
struct starpu_codelet hello_world_cl = {
.cpu_funcs = { hello_world_cpu },
.cuda_funcs = { hello_world_cuda }
};
int main()
{
if (starpu_init(NULL) != 0)
printf("Failed to initialize Starpu.\n");
starpu_task_insert(&hello_world_cl, 0);
starpu_task_wait_for_all();
starpu_shutdown();
return 0;
}
|
That is, we must add a task implementation (hello_world_cuda) that inserts a CUDA kernel (say_hello) to the provided local CUDA stream (stream).
Note how the naive eager scheduler prefers to use the CPU implementation where as the GPU-aware dm scheduler prefers the GPU:
$ nvcc -o my_program my_program.cu -lstarpu-1.3 -Xcompiler="-Wall"
$ STARPU_SCHED=eager ./my_program
The host says, Hello world!
$ STARPU_SCHED=dm ./my_program
A device says, Hello world!
If we want to obtain a reasonable performance using GPUs, we must define a performance model for each codelet:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | struct starpu_codelet
{
uint32_t where;
int (*can_execute)(unsigned workerid, struct starpu_task *task, unsigned nimpl);
enum starpu_codelet_type type;
int max_parallelism;
starpu_cpu_func_t cpu_func STARPU_DEPRECATED;
starpu_cuda_func_t cuda_func STARPU_DEPRECATED;
starpu_opencl_func_t opencl_func STARPU_DEPRECATED;
starpu_cpu_func_t cpu_funcs[STARPU_MAXIMPLEMENTATIONS];
starpu_cuda_func_t cuda_funcs[STARPU_MAXIMPLEMENTATIONS];
char cuda_flags[STARPU_MAXIMPLEMENTATIONS];
starpu_opencl_func_t opencl_funcs[STARPU_MAXIMPLEMENTATIONS];
char opencl_flags[STARPU_MAXIMPLEMENTATIONS];
starpu_mic_func_t mic_funcs[STARPU_MAXIMPLEMENTATIONS];
starpu_mpi_ms_func_t mpi_ms_funcs[STARPU_MAXIMPLEMENTATIONS];
const char *cpu_funcs_name[STARPU_MAXIMPLEMENTATIONS];
int nbuffers;
enum starpu_data_access_mode modes[STARPU_NMAXBUFS];
enum starpu_data_access_mode *dyn_modes;
unsigned specific_nodes;
int nodes[STARPU_NMAXBUFS];
int *dyn_nodes;
struct starpu_perfmodel *model;
struct starpu_perfmodel *energy_model;
unsigned long per_worker_stats[STARPU_NMAXWORKERS];
const char *name;
unsigned color;
int flags;
int checked;
};
|
In the simplest case, the model can use the run time history to predict the execution times:
1 2 3 | struct starpu_perfmodel model = {
.type = STARPU_HISTORY_BASED
};
|
StarPU also supports regression based performance models (STARPU_REGRESSION_BASED, STARPU_NL_REGRESSION_BASED, STARPU_MULTIPLE_REGRESSION_BASED):
1 2 3 | struct starpu_perfmodel model = {
.type = STARPU_REGRESSION_BASED
};
|
By default, StarPU calculates the model argument (base) from the amount of memory required to store all involved data handles. However, a programmer may provide a custom function for this.